安装部署
获取文件
wget https://dlcdn.apache.org/zeppelin/zeppelin-0.10.0/zeppelin-0.10.0.tgz
解压
tar zxvf zeppelin-0.10.1-bin-all.tgz
更改目录名称
mv zeppelin-0.10.1-bin-all zeppelin
自定义zeppelin 绑定address和port
修改 /zeppelin/conf/zeppelin-site.xml文件,地址原来为127.0.0.1,远程是不能访问的,改为0.0.0.0,端口改为没有被占用的,我这里用的18080
<property>
<name>zeppelin.server.addr</name>
<value>0.0.0.0</value>
<description>Server binding address</description>
</property>
<property>
<name>zeppelin.server.port</name>
<value>18080</value>
<description>Server port.</description>
</property>
建立对应日志和pid目录
mkdir zeppelin/logs
mkdir zeppelin/run
启动zeppelin:
bin/zeppelin-daemon.sh start
自启动配置
配置zeppeline环境
下面两个需要在环境变量中配置,已有的可以忽略
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_291.jdk/Contents/Home
export HADOOP_CONF_DIR=/usr/local/Cellar/hadoop/3.3.1/libexec/etc/hadoop
配置Flink Interpreter
(参考)[https://zeppelin.apache.org/docs/0.8.0/usage/interpreter/interpreter_binding_mode.html]
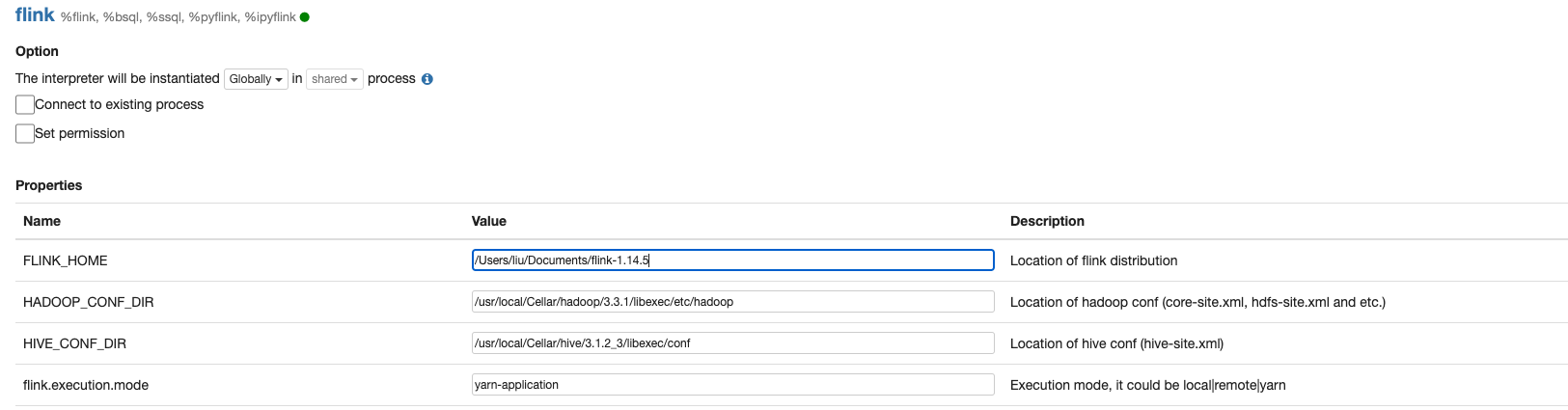
页面右上角点击用户中的Interpreter,搜索Flink 点击edit标志,编辑其中需要修改的参数
必须填写参数:
FLINK_HOME
HADOOP_CONF_DIR
HIVE_CONF_DIR
flink.execution.mode
需要注意Interpreter绑定方式以及flink.execution.mode
Flink Interpreter binding决定了创建Flink Cluster的逻辑
flink.execution.mode 决定了我们以何种方式去连接Flink Cluster
Interpreter Binding (重要)
Interpreter Process 是一个 JVM 进程
-
Shared Mode(共享模式):默认模式,可以共享数据和状态。这种模式适用于资源消耗较小的解释器,可以提高性能和资源利用率。所有用户提交都给了同一个Flink Interpreter 也就是同一个Flink Cluster
-
Isolated Mode(隔离模式):在隔离模式下,每个 Zeppelin 解释器实例都运行在其自己的容器或虚拟机中,完全隔离于其他解释器和环境。这种模式提供了最高级别的隔离和安全性,但也会导致更高的资源消耗。
Per Note Isolated:
意味着每个笔记都会创建一个Flink Cluster
Per User Isolated:
意味着每个用户创建一个Flink Cluster
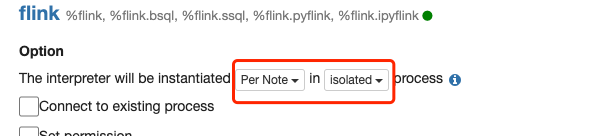
将Interpreter Binding模式修改为Isolated per Note,在这种模式下,每个Note在执行时会分别启动Interpreter进程,类似于Flink on YARN的Per-job模式
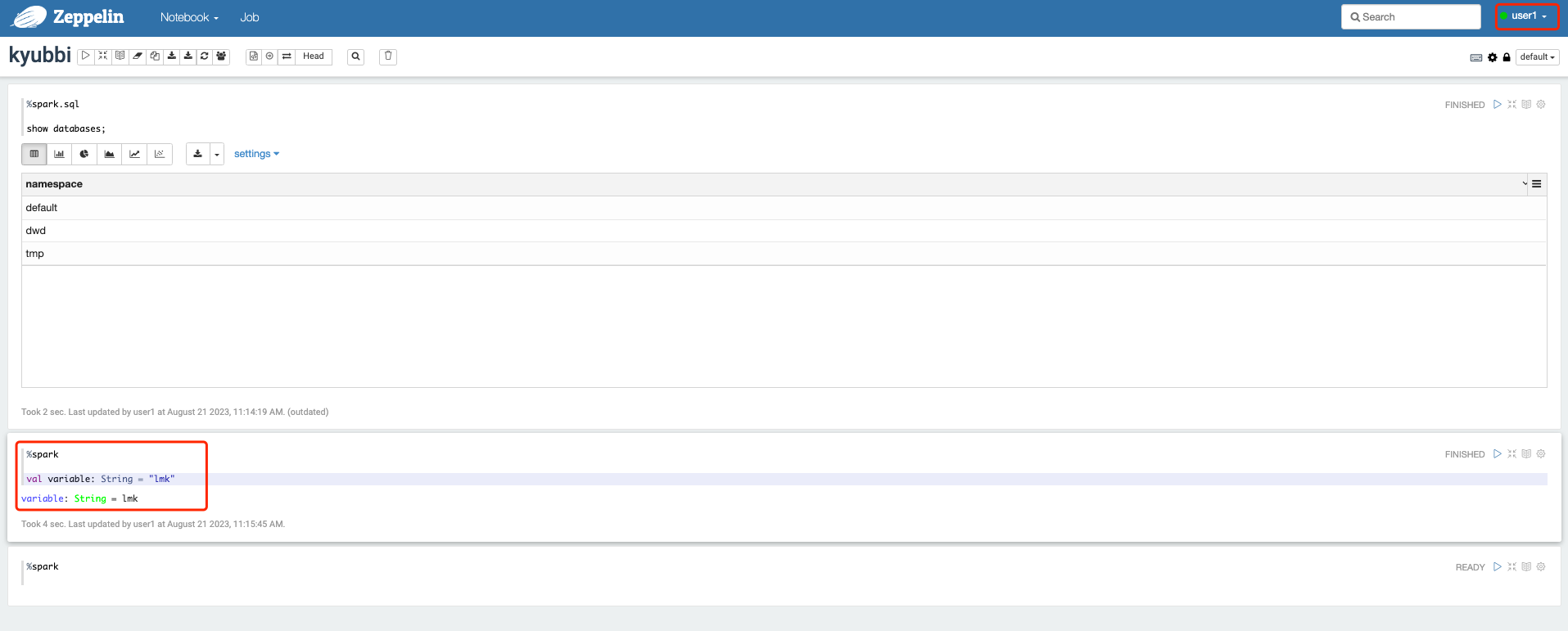
使用shared global样例
使用用户user1创建一个变量variable,使用admin用户在一个新的笔记本中输出这个变量

Flink Execution Mode
Local
会创建一个miniCluster在本机
Remote Mode
连接一个远程Flink Cluster,需要单独配置flink.execution.remote.host and flink.execution.remote.port
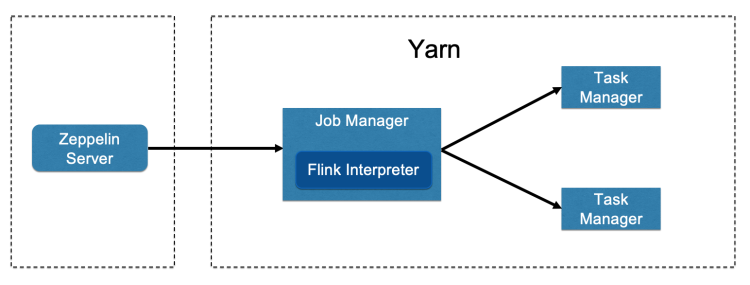
Yarn Mode(Deprecated)
会在Yarn集群中创建一个Flink Session Cluster,之后便可以向其中提交任务。他的生命周期是Zeppelin控制的。你启动Flink Interpreter的时候就创建这个Yarn Session Cluster,当你停止或者重启Flink Interpreter的时候就会销毁这个Yarn Session Cluster。
如果是Shared 模式,所有的job都会运行一个Flink Yarn Session Cluster里。如果是Per User Isolated,那么每个用户都会运行一个Flink Yarn Session Cluster,如果是Per Note Isolated,那么每个Note都对运行一个Flink Yarn Session Cluster。
Yarn Application
该模式会把Flink interpreter进程跑在Yarn的JobManager里,如果出现过多的Interpreter进程不会对Zeppelin这台机器造成过多压力
Flink检查点相关
CheckPoint 相关
两种方式开启:
- %flink.conf 启用checkpoint
- Scala API 启用checkpoint
%flink.conf
%flink.conf
%%pipeline.time-characteristic用于配置流数据处理的时间属性,`ProcessingTime`(处理时间),`EventTime`(事件时间),`IngestionTime`(摄入时间)%%
pipeline.time-characteristic EventTime
%%checkpoint 时间间隔%%
execution.checkpointing.interval 10000
execution.checkpointing.externalized-checkpoint-retention RETAIN_ON_CANCELLATION
state.backend filesystem
state.checkpoints.dir file:///tmp/flink/checkpoints
%flink
%flink
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.runtime.state.filesystem.FsStateBackend
%%设置为事件时间戳之后,需要正确处理事件时间戳和水印%%
senv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
senv.enableCheckpointing(10 * 1000)
senv.setStateBackend(new FsStateBackend("file:///tmp/flink/checkpoints"));
val chkConfig = senv.getCheckpointConfig
chkConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
请务必配置 execution.checkpointing.externalized-checkpoint-retention 为 RETAIN_ON_CANCELLATION,否则的话当你的Flink 集群退出以后,checkpoint数据也就丢失了,只有设置了 RETAIN_ON_CANCELLATION 才会保留checkpoint数据。
设置checkpoint路径:
两种方式,一种在%flink.conf中配置,另一种是在pararaph中配置
%flink.conf 里设置有一个限制checkpoint 路径,你的flink session cluster里只能有一个flink job,因为你只能在%flink.conf 设置一次 execution.savepoint.path,否则任务间可能会互相影响。
%%pararaph 设置方式%%
%flink.ssql(execution.checkpoint.path=hdfs:///checkpoint)
从Checkpoint恢复Job
支持手动自动回复两种方式
手动恢复checkpoint:
默认checkpoint只保存一个,state.checkpoints.num-retained 设置保存次数
可以在%flink.conf中或者pararaph设置同步参数 execution.savepoint.path
自动恢复checkpoint:
配置下面参数,会自动从最新的checkpoint开始
resumeFromLatestCheckpoint=true
Savepoint相关
savepoint 是我们cancel Paragraph的时候自动保存,配置savepoint和上面checkpoint类似,需要注意的是参数名称修改即可
开启:savepointDir=...
自动恢复:resumeFromLatestCheckpoint=true
注意
如果你没有可用的checkpoint或者savepoint数据,那么只能重新开始job,这个时候你需要设置 resumeFromLatestCheckpoint 和 resumeFromSavepoint 都为 false
Spark on Zeppelin
Spark interpreter 直连
1.首先确定spark能正常提交任务到yarn上,可以使用下面demo测试
bin/spark-submit \
--master yarn \
--class org.apache.spark.examples.SparkPi \
examples/jars/spark-examples_2.12-3.2.1.jar \
10
2.如果提交任务正确,接下来需要在Interpreters中设置spark相关的Interpreter,下面红框中的配置必须要设置
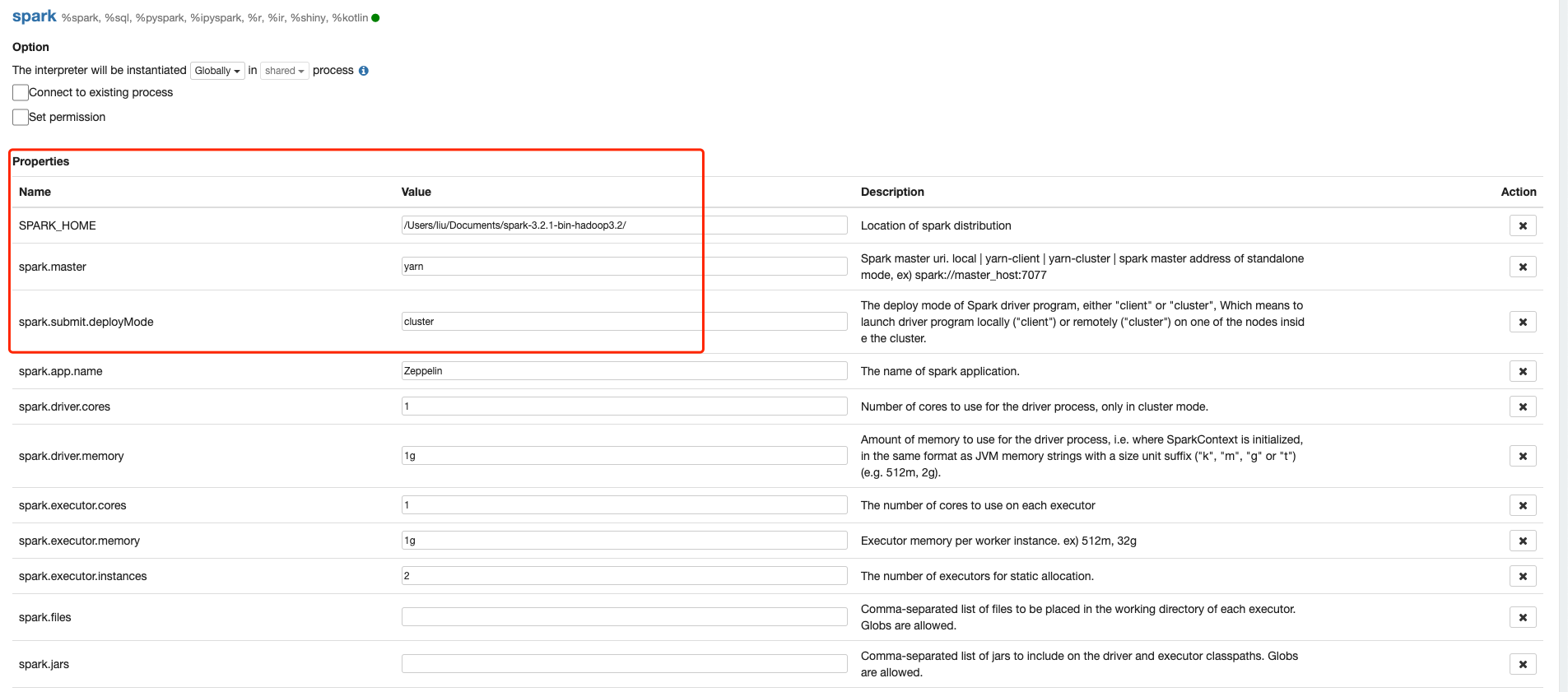
除了上面的配置,有一个配置需要注意一下:
zeppelin.spark.run.asLoginUser
当这个值为true的时候,代表使用登录zeppelin用户提交任务,这时候需要保证zeppelin用户有权限提交任务到yarn队列,以及访问库表。
Spark3.x版本配置Yarn模式时需要按照以下配置,来源
| Mode | spark.master | spark.submit.deployMode |
|---|---|---|
| Yarn Client | yarn | client |
| Yarn Cluster | yarn | cluster |
还有一些和Spark运行任务时相关的配置,可以看下表
| spark.driver.memory | 1g | Amount of memory to use for the driver process, i.e. where SparkContext is initialized, in the same format as JVM memory strings with a size unit suffix ("k", "m", "g" or "t") (e.g. 512m, 2g). |
| spark.executor.cores | 1 | The number of cores to use on each executor |
| spark.executor.memory | 1g | Executor memory per worker instance. e.g. 512m, 32g |
| spark.executor.instances | 2 | The number of executors for static allocation |
此时已经可以执行Spark任务了


需要注意的是这个spark interpreter会一直存在yarn上,只有在interpreter编辑页面restart的时候会断开,这样的话适合多人的人来连接同一个spark interpreter,这样保证资源随时可用,不浪费。
通过JDBC interpreter连接Kyuubi
首先需要保证通过beeline 连接 kyuubi 可以提交spark任务到yarn上,参考这个Spark on Kyuubi With Yarn
检查发现最新版本的Zeppelin是2022年2月28号发布的,这个版本的jdbc interpreter不支持kyuubi,相关pr是2022年9月提交合并的https://github.com/apache/zeppelin/pull/4392
如果直接使用最新release 也就是2022/2/28号0.10.0版本的zeppelin,使用jdbc interpreter连接10009 kyuubi端口,报错如下:
({SchedulerFactory15} NotebookServer.java[onStatusChange]:1984) - Job paragraph_1692587741619_1396685451 is finished, status: ERROR, exception: null, result: %text java.lang.ClassCastException: org.apache.kyuubi.jdbc.hive.KyuubiStatement cannot be cast to org.apache.hive.jdbc.HiveStatement
at org.apache.zeppelin.jdbc.hive.HiveUtils.startHiveMonitorThread(HiveUtils.java:63)
at org.apache.zeppelin.jdbc.JDBCInterpreter.executeSql(JDBCInterpreter.java:805)
at org.apache.zeppelin.jdbc.JDBCInterpreter.internalInterpret(JDBCInterpreter.java:939)
at org.apache.zeppelin.interpreter.AbstractInterpreter.interpret(AbstractInterpreter.java:55)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:110)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:860)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:752)
at org.apache.zeppelin.scheduler.Job.run(Job.java:172)
at org.apache.zeppelin.scheduler.AbstractScheduler.runJob(AbstractScheduler.java:132)
at org.apache.zeppelin.scheduler.ParallelScheduler.lambda$runJobInScheduler$0(ParallelScheduler.java:46)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
所以我们需要自己编译支持kyuubi的zeppelin代码,刚开始我尝试的是master分支,发现master分支上面有很多测试代码和测试的功能,不仅影响编译,还不稳定,切换为0.10.0分支重新打包,踩了很多很多坑,下面是相关报错的总结以及如何修改
编译打包遇到的问题
打包前一定设置成jdk8
export JAVA_HOME=/usr/lib/jvm/java/
- 将所有pom文件中的
<>0.10.1-SNAPSHOT</version>
更改为<version>0.10.1</version>
很多maven源网站都没有对应的SNAPSHOT包,所以必须删除,否则打包会失败
可以参考下面这个python脚本,递归替换指定目录下pom结尾的文件中所有指定字符
import os
def replace_version_in_pom_files(root_dir, old_version, new_version):
for root, dirs, files in os.walk(root_dir):
for file in files:
if file.endswith("pom"):
file_path = os.path.join(root, file)
replace_in_file(file_path, old_version, new_version)
def replace_in_file(file_path, old_version, new_version):
with open(file_path, 'r') as file:
content = file.read()
updated_content = content.replace("<version>{}</version>".format(old_version), "<version>{}</version>".format(new_version))
with open(file_path, 'w') as file:
file.write(updated_content)
# 使用示例
root_directory = '/data/lmk/test'
# root_directory = '/Users/liu/tmp'
old_version = '0.10.1-SNAPSHOT'
new_version = '0.10.1'
if __name__ == '__main__':
replace_version_in_pom_files(root_directory, old_version, new_version)
- 修改根目录下pom中的module,注释掉不需要要的,可以参考下面样例,注意其中markdown等是必须保存的,否则编译报错
展开/收起
- 如果你的机器是在国内,并且编译zeppelin-web的时候报错了,那么可以尝试在zeppelin-web打包时卡主太久的话,可以先ctrl+c退出,首先检查代理是否正常,因为zeppelin-web编译的时候是用的他自己下载的指定版本的node和npm,对其zeppelin-web目录下node设置npm国内镜像,执行下面指令,但是速度还是很慢,原因未知。
cd zeppelin/zeppelin-web/node
./npm config set registry https://registry.npm.taobao.org
进入到zeppelin根目录,执行mvn package -DskipTests -rf :zeppelin-web,注意这里mvn后面不要加clean命令,否则会重新下载node,我们配置的镜像也就没用了。
手动编译zeppelin-web可能用到的命令
清理缓存
/Users/liu/zeppelin-0.10.0/zeppelin-web/node/node /Users/liu/zeppelin-0.10.0/zeppelin-web/node/node_modules/npm/bin/npm-cli.js cache clean --force
安装
/Users/liu/zeppelin-0.10.0/zeppelin-web/node/node /Users/liu/zeppelin-0.10.0/zeppelin-web/node/node_modules/npm/bin/npm-cli.js --registry https://registry.npm.taobao.org install --no-lockfile
设置相关参数
./node/npm --node="/Users/liu/zeppelin-0.10.0/zeppelin-web/node/node" config set registry https://registry.npm.taobao.org
./node/npm --node="/Users/liu/zeppelin-0.10.0/zeppelin-web/node/node" config set scripts-prepend-node-path true
查看源
./node/npm --node="/Users/liu/zeppelin-0.10.0/zeppelin-web/node/node" get registry
测试bower install
注意他用的node是你本机的还是外部的
/Users/liu/zeppelin-0.10.0/zeppelin-web/node_modules/bower/bin/bower install --silent --allow-root
- 如果进行编译zeppelin的用户是有root权限,那么编译zeppelin-web的时候会报错,需要修改zeppelin-web下的package.json,将scripts中的
clean,postinstall,prebuild,build:dist,build:ci,也就是前五行,替换为下面内容
"clean": "rimraf dist && rimraf .tmp",
"postinstall": "bower install --silent --allow-root",
"prebuild": "npm-run-all clean lint:once",
"build:dist": "npm-run-all prebuild && bower install --silent --allow-root && grunt pre-webpack-dist && webpack && grunt post-webpack-dist",
"build:ci": "npm-run-all prebuild && bower install --silent --allow-root && grunt pre-webpack-ci && webpack && grunt post-webpack-dist",
-
然后进入zeppelin-web下执行
echo '{ "allow_root": true }' > ~/.bowerrc -
PhantomJS相关问题
PhantomJS not found on PATH
Downloading https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-macosx.zip
把上面那个对应包放到错误中提示的临时目录中 -
不能执行git相关代理
不能执行以下相关操作
git config --global http.proxy http://10.218.34.51:8889
git config --global http.proxy https://10.218.34.51:8889
- 报错
silly fetchPackageMetaData fatal: could not create leading directories of ...git修改权限 chmod 555 /root
编译完成之后的配置
编译完成之后进入zeppelin根目录,执行下面命令启动zeppelin
bin/zeppelin-daemon.sh start
创建一个叫kyuubi的jdbc interpreter,注意其中default.driver配置为org.apache.kyuubi.jdbc.KyuubiHiveDriver
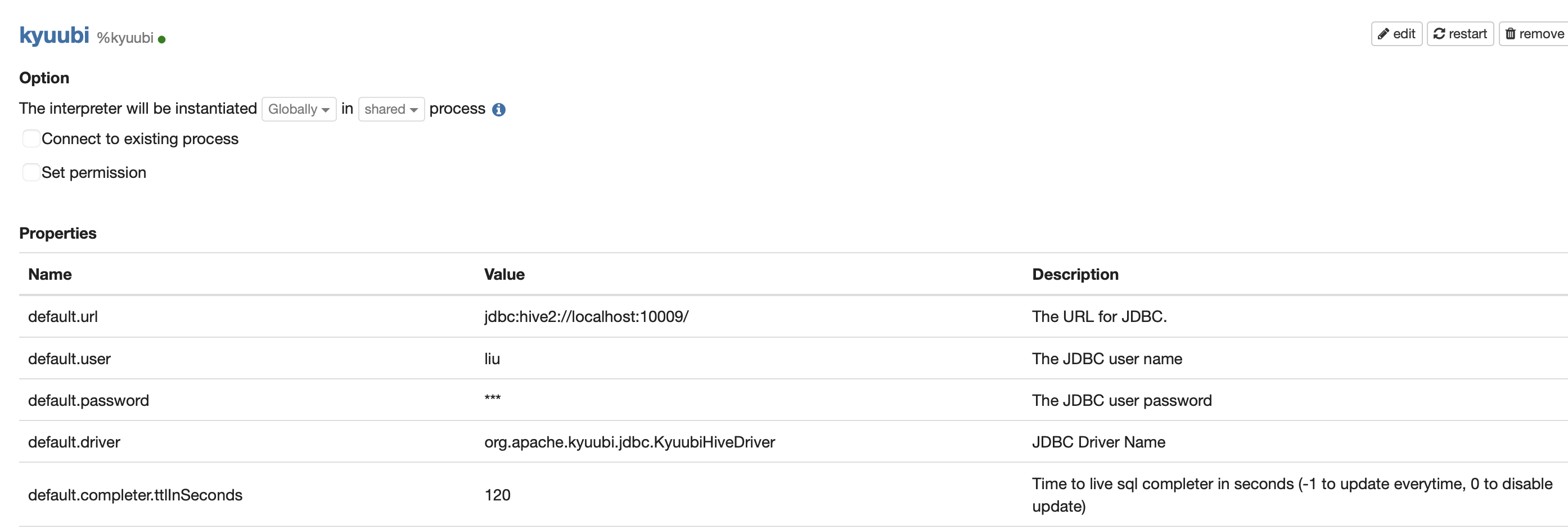
在最下面dependencies中配置两个包org.apache.kyuubi:kyuubi-hive-jdbc-shaded:1.5.2-incubating
org.apache.hive:hive-jdbc:3.1.2
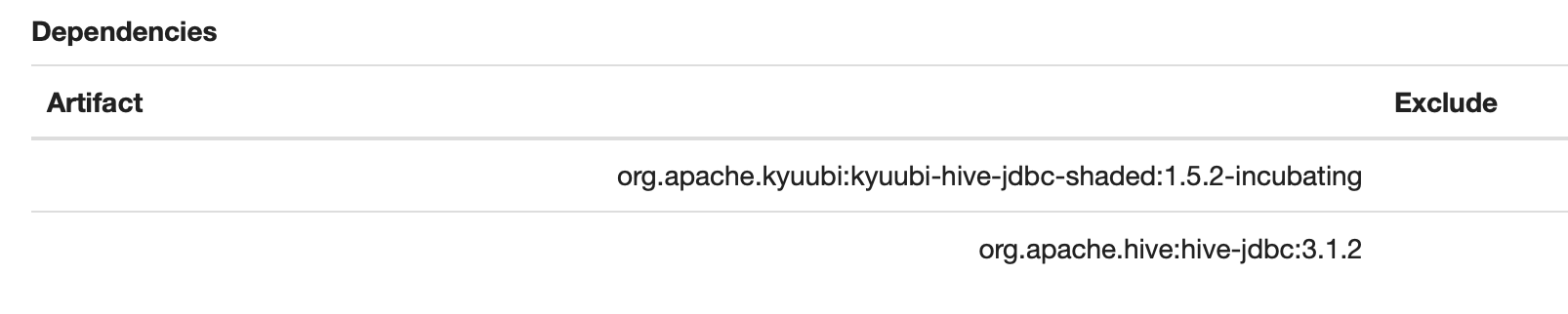
在图中增加配置default.proxy.user.property - hive.server2.proxy.user
该配置允许用户以登录zeppelin的账号提交任务,这样可以自然的和ranger权限集成,直接使用ranger中的用户名当做zeppelin用户名,而不用单独配置zeppelin用户权限。
Kubernetes
官方镜像
1.拉取官方镜像
docker pull apache/zeppelin:0.10.0
2.使用docker 直接运行
docker run -d --name zeppelin0.10 -p 8888:8080 apache/zeppelin:0.10.1
访问 http://adt-phx-test-bd-sjh:8888/#/ 即可
手动打包镜像
docker相关命令
重命名官方镜像为zeppelin-server
docker tag e8b5b40b7720 apache/zeppelin-server:0.10.1
删除旧镜像名称
docker rmi apache/zeppelin:0.10.1
删除旧容器命令
docker rm containerId
k8s相关命令
查看pod
kubectl get pod
上线配置
kubectl apply -f zeppelin-server.yaml
下线配置
kubectl delete -f zeppelin-server.yaml
k8s apply yaml失败查看详情
kubectl describe pod zeppelin-server-55987cb744-5tkgm
进入到pod中
kubectl exec -it zeppelin-server-775669b959-q95m6 -- /bin/bash
cri-o://c5ce66fc9329abc2fd78c136889876d6d854a64b934fc44118f3f8237edf3f1a
kubectl logs -f zeppelin-server-664c98b6cd-ftbd8
向nexus推送镜像
注意REPOSITORY需要改成adt-nexus:8086/zeppelin-server
docker push adt-nexus:8086/zeppelin-server:0.10.0
k8s启动zeppelin命令
需要将zeppelin-server-5459cf8b56-jrwn4替换为自己的zeppelin pod id,需要注意的是如果你修改过zeppelin的端口,那么你需要将8080:80替换成8080:修改的端口,比如我这里是8080:18081,然后访问本机8080端口即可。
kubectl port-forward zeppelin-server-664c98b6cd-v799j 8080:18081 --address 0.0.0.0
编译镜像
编译zeppelin-distribution
需要改写${zeppelin_home}/scripts/docker/zeppelin-server/Dockerfile文件
模板:Zeppelin-Distribution-Dockerfile
主要删除了maven打包过程,直接将我们打包好的文件复制到镜像指定路径下
cd ${zeppelin_home}
docker build -t zeppelin-distribution:0.10.0 -f ./Dockerfile .
编译zeppelin-server
需要改写${zeppelin_home}/scripts/docker/zeppelin-server/Dockerfile文件
模板:Zeppelin-Server-Dockerfile
修改:
1.将openjdk-8-jre-headless修改为了openjdk-8-jdk-headless,jre中缺少jdk-tools.jar,导致配置interpreter的时候下载依赖会失败
2.配置kyuubi的时候需要下载两个包,分别是kyuubi-hive-jdbc和hive-jdbc,我们先在本地下载下来这两个包,然后使用本地maven安装这两个包
将这两个目录预先放置在${zeppelin_home}/scripts/docker/zeppelin-server/目录下,Dockerfile创建指定目录,并将两个目录内容放入到对应目录下
cd ${zeppelin_home}/scripts/docker/zeppelin-server
docker build -t zeppelin-server:0.10.0 -f ./Dockerfile .
编译zeppelin-interpreter
需要改写${zeppelin_home}/scripts/docker/zeppelin-interpreter/Dockerfile文件
模板: Zeppelin-Interpreter-Dockerfile
修改:
注释掉conda config --add channels conda-forge &&,增加conda install --channel https://conda.anaconda.org/conda-forge apache-beam,否则ubuntu下载源之间会相互冲突。
cd scripts/docker/zeppelin-interpreter
docker build -t zeppelin-interpreter:0.10.0 -f ./Dockerfile .
启动zeppelin on k8s
需要修改${zeppelin_home}/data/lmk/zeppelin-0.10.0/k8s/zeppelin-server.yaml文件
模板:Zeppelin-Server-Yaml
修改:
1.ZEPPELIN_K8S_CONTAINER_IMAGE: registy.adtiming.com/zeppelin-interpreter:0.10.0
2.Deployment中增加两个configmap
- name: configmap-interpreter
configMap:
name: my-configmap-interpreter
- name: configmap-shiro
configMap:
name: my-configmap-shiro
3.配置deployment中spec.template.spec.containers.volumeMounts相关挂载到pod内部文件中,文件内具体内容见下面#挂载用户和配置文件
- name: configmap-interpreter
mountPath: /opt/zeppelin/conf/interpreter-hot.json
subPath: interpreter-hot.json
- name: configmap-shiro
mountPath: /opt/zeppelin/conf/shiro.ini
subPath: shiro.ini
4.执行command的时候将挂载的interpreter-hot.json复制到interpreter.json中
command: ["sh", "-c", "cp $(ZEPPELIN_HOME)/conf/interpreter-hot.json $(ZEPPELIN_HOME)/conf/interpreter.json && $(ZEPPELIN_HOME)/bin/zeppelin.sh"]
5.在zeppelin-server镜像配置下面添加imagePullPolicy: Always,这样每次都会拉取新的镜像
挂载用户和配置文件
参考:Kyuubi-Configmap
挂载interpreter-hot.json,其中配置了kyuubi连接器,按照上面#启动zeppelin on k8s中2、3点挂载文件,4点更新文件
参考:Zeppelin-Shiro-Configmap
挂载shiro.ini,其中配置了用户相关的配置文件
权限相关
Zeepline 使用Apache Shiro 作为权限管理
开启Shiro
cp conf/shiro.ini.template conf/shiro.ini
vim conf/shiro.ini
在[users]选项下面配置用户
admin = password1, admin
user1 = password2, role1, role2
user2 = password3, role3
user3 = password4, role2
等号前面是用户名称,等号后面是密码,再后面是角色role
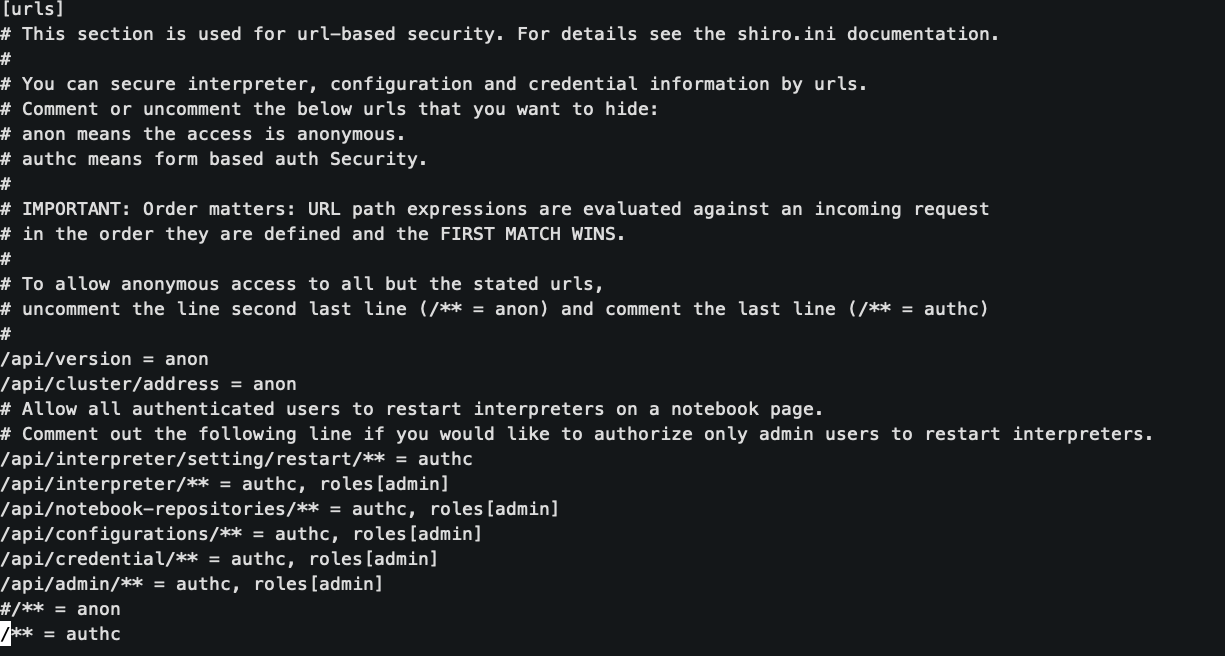
默认只有admin组内用户可以访问interpreter界面,shiro.ini文件中相关配置如下图,来源
设置笔记权限,右上角锁的图标,点击之后分别选取读,写,执行相关权限


遇到的问题
1.Flink 1.17不支持
指定Flink-1.17 运行报错 Caused by: java.lang.Exception: Flink version: '1.17.0' is not supported yet
但是paimon推荐使用最新的flink,这里需要进行取舍,后面测试改用flink-1.14.5
2.Caused by: java.lang.NoSuchFieldError: ALLOW_UNALIGNED_SOURCE_SPLITS
在zeppline执行sql报错,这个是jar冲突问题,需要检查我们flink lib目录下所有的jar都是符合我们当前flink版本的,包括kafka相关的paimon相关的都需要版本正确
原先使用的是paimon-flink-1.14-0.4.0-incubating.jar改成更新的paimon-flink-1.14-0.5-20230808.002215-117.jar 以及flink-sql-connector-kafka_2.12-1.17.0.jar 切换为flink-sql-connector-kafka_2.12-1.14.5.jar后即可