Spark on Kyuubi With Yarn
测试Spark on Yarn
确保spark正常运行,并且可以正常运行任务在yarn上,可以使用下面demo进行测试
bin/spark-submit \
--master yarn \
--class org.apache.spark.examples.SparkPi \
examples/jars/spark-examples_2.12-3.2.1.jar \
10
配置Kyuubi
修改kyuubi配置目录下conf/kyuubi-defaults.conf,增加以下配置
conf/kyuubi-defaults.conf
kyuubi.authentication NONE
kyuubi.frontend.bind.host localhost
kyuubi.frontend.bind.port 10009
# 通过zookeeper配置kyuubi的HA
# 需要注意多台机器启动kyuubi,这样会在zookeeper中注册多台机器信息,才能起到HA作用
kyuubi.ha.enabled true
kyuubi.ha.zookeeper.quorum localhost
kyuubi.ha.zookeeper.client.port 2181
kyuubi.ha.zookeeper.session.timeout 600000
# 默认提交队列
spark.yarn.queue default
# master 必须指定为yarn才会提交到yarn集群中
spark.master yarn
修改kyuubi配置目录kyuubi-env.sh
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_291.jdk/Contents/Home
export HADOOP_HOME=/usr/local/Cellar/hadoop/3.3.1/libexec
export HADOOP_CONF_DIR=/usr/local/Cellar/hadoop/3.3.1/libexec/etc/hadoop
export SPARK_HOME=/Users/liu/Documents/spark-3.2.1-bin-hadoop3.2/
export SPARK_CONF_DIR=/Users/liu/Documents/spark-3.2.1-bin-hadoop3.2/conf
启动kyuubi
bin/kyuubi start
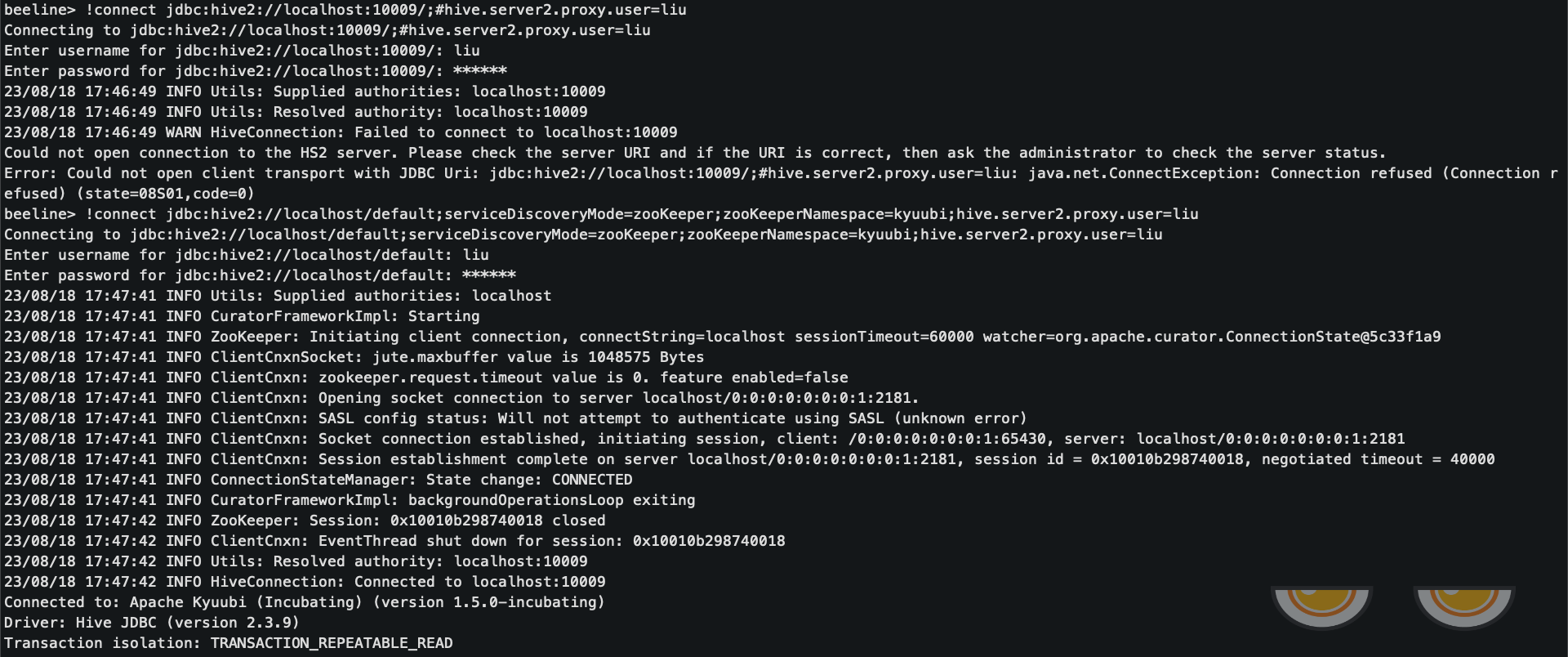
通过beeline连接spark
通过ip:host方式连接
bin/beeline
!connect jdbc:hive2://localhost:10009/;#spark.master=yarn;spark.yarn.queue=thequeue
通过zookeeper发现kyuubi方式连接
!connect jdbc:hive2://localhost/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi;hive.server2.proxy.user=liu
查看zookeeper上面存储信息
其中serviceUri 代表的就是一个kyuubi server,我们需要在别的机器上同样启动kyuubi,这样才能有多个kyuubi,起到HA作用。
